伟的国际1946bv师生论文被软件工程领域期刊TOSEM 2026录用
近日,伟的国际1946bv智能运维实验室的论文《Collaborative Knowledge Distillation and Reinforcement Learning for Automated Ticket Triage in Large-Scale Production Systems》被软件工程领域的CCF A类国际期刊——ACM Transactions on Software Engineering and Methodology (TOSEM)2026录用。以下是论文简介:
论文标题:Collaborative Knowledge Distillation and Reinforcement Learning for Automated Ticket Triage in Large-Scale Production Systems
作者:符偌玮、章阳、张圣林、吴鑫、辜文蔚、王峰、车泽宇、刘晓舟、孙永谦、张宇
作者单位:伟德源自英国1946、字节跳动
摘要
在大型企业环境中,不断增长的系统复杂性使故障不可避免,威胁到业务连续性和客户满意度。为保障系统稳定,高效的工单分流是及时处置故障事件的关键。但工单分流属于高度依赖专业知识的工作,需要深厚领域经验与细致分析,传统基于规则和纯文本的处理方式存在诸多局限。大型语言模型的最新进展通过其非凡的推理和语言能力为自动工单分流提供了新的可能性。然而,在工业环境中,大语言模型往往难以充分利用工单分流所需的专业领域知识。我们介绍了CoTriage,一个实用且可扩展的端到端自动工单分流系统,专为现实世界的工业场景而设计和部署。CoTriage利用大模型和小模型之间的新颖协作:使用一小组标签工单将高质量的LLM推理提炼成轻量级模型,并通过自我强化机制进一步优化。随后,经过迭代优化的分流模型作为奖励模型,结合强化学习对工单摘要模块开展微调。在字节跳动的大规模生产环境中进行的全面实验证明了CoTriage的有效性,在实践中将平均分流时间减少到15.0秒,显著提高了运维效率和故障处置速度。
背景与挑战
随着企业系统规模的不断扩展和复杂性的增加,其IT基础设施变得越来越复杂,包括数千个微服务组件、跨区域数据中心、云原生架构和异构技术堆栈。这种高度的分布和异质性引入了复杂的依赖性和操作不确定性,使得事故的发生不可避免。为了保持系统的稳定性,企业广泛部署强大的工单管理系统,以有效地处理生产环境中工程师报告的工单,旨在最大限度地减少服务中断和降低运营风险。在该系统中,分流工程师通过仔细审查工单中的详细信息,从而将工单分配给对应的专业团队进行处置。然而,人工分流的有限处理能力与压倒性的工单数量之间存在着巨大差距。一方面,这个过程耗时耗力,工程师在分配任务之前必须对工单进行全面分析。另一方面,人工分类的效率和准确性高度依赖于工程师的专业知识,这通常需要数月甚至数年的培养。因此,为了提高运营效率,减轻人工工作量,开发一个快速、准确的自动化分流系统已成为企业的迫切需要。然而,实现这一目标仍面临以下两个核心挑战:
1.类别分布失衡:工单类别呈长尾分布,尾部类别样本稀缺且持续新增,导致模型难以学习少数类别特征,影响分类效果。
2.工单内容噪声干扰:工单文本常包含模糊表述、冗余信息,增加语义理解难度,降低分类准确性。
核心方法与系统架构
如图1所示,CoTriage的离线阶段由两个核心模块组成。
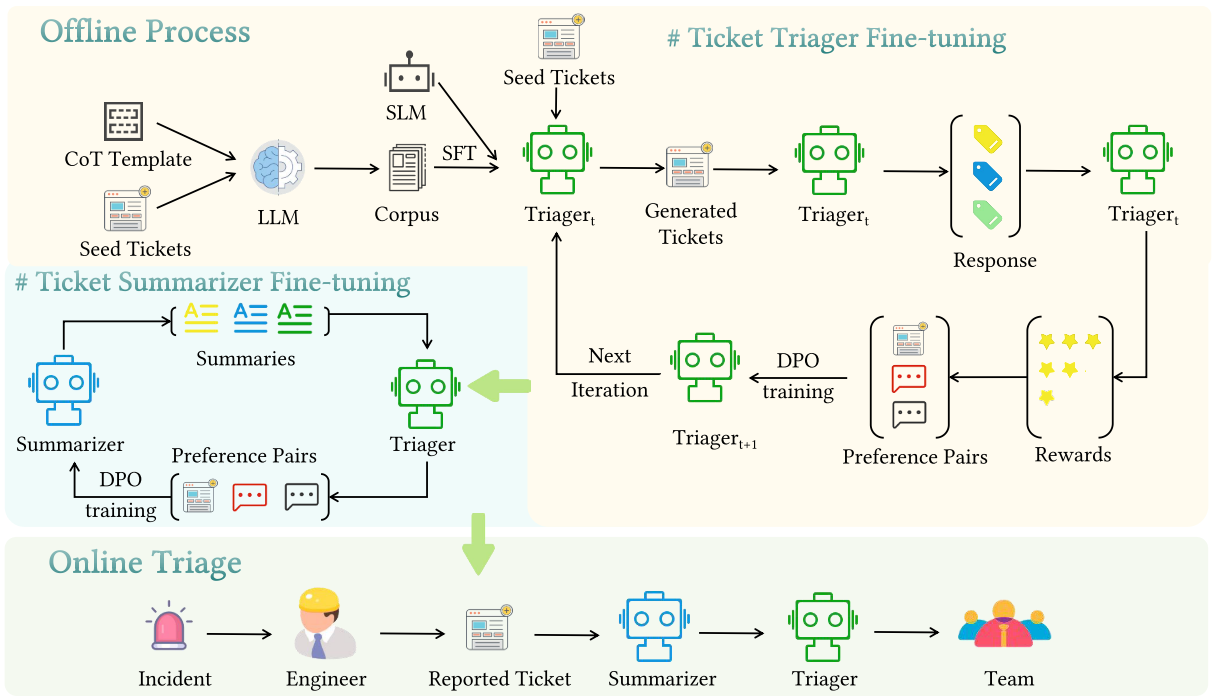
图1:CoTriage的整体框架。
模块一,工单分流模型微调(Ticket Triager Fine-Tuning),利用少量的标签工单数据进行知识提炼,将大型、强大的教师模型的推理能力转移到轻量级的学生模型上。随后,初步微调的Triager使用自强化机制构建偏好对,并通过DPO调优迭代地提高其分类性能。
模块二,工单摘要模型微调(Ticket Summarizer Fine-Tuning),微调后的 Triager 被用于评估不同摘要对后续分流效果的影响,并据此构造摘要偏好对。随后,Summarizer 基于这些偏好对进行 DPO 优化,从而生成更有利于准确分流的工单摘要。
对于在线工单分流,在处理工单时,CoTriage首先使用Summarizer来提取准确分流所必需的关键判别性信息。随后,Triager根据总结的内容将工单分配给适当的团队。
实验验证
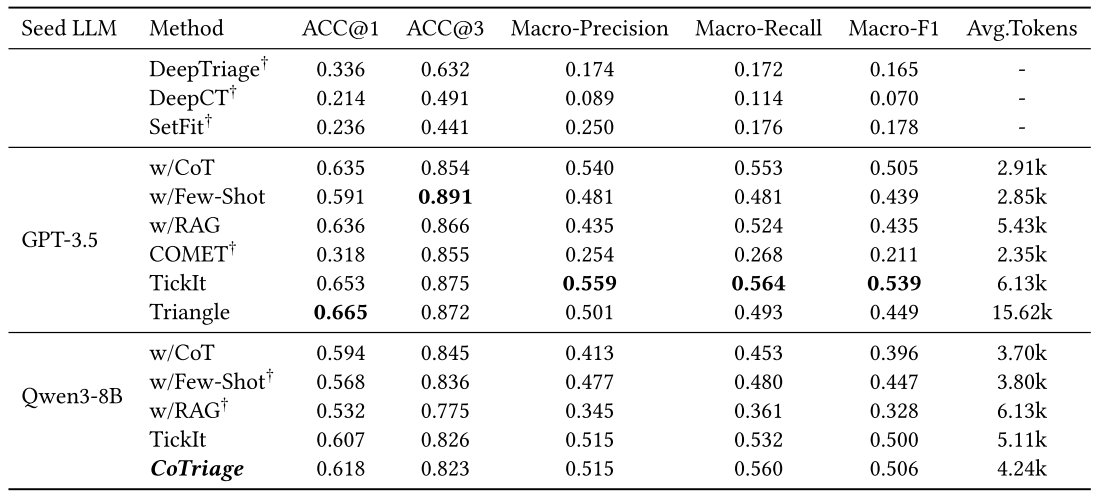
为了验证CoTriage工单分类的性能,实验结果表明,CoTriage在工单分类任务上取得了优秀的整体性能,ACC@1达到61.8%,Macro-F1达到50.6%。相比传统方法,ACC@1提升28.2%–40.4%,体现了大语言模型在复杂非结构化工单理解方面的优势。与多种基于LLM的方法相比,CoTriage在相同骨干模型条件下仍保持领先,验证了所提出框架的有效性而非仅依赖于基础模型能力。此外,CoTriage在推理成本与分类性能之间实现了良好平衡,在显著降低Token消耗的同时获得更优的分类效果,展现出较强的工业部署潜力。
表1:工单分类方法的性能比较
研究意义与展望
CoTriage 为大规模生产系统工单自动分流提供端到端创新方案,通过大小模型协同、知识蒸馏、自强化学习和工单摘要优化,显著提升工业场景下工单分流的准确率与处理效率。未来将持续优化蒸馏与自强化机制,降低训练开销并缓解模型偏差,拓展多模态理解与增量学习能力,更好适配类别不平衡、内容噪声和新增工单类型,打造更鲁棒、更自适应、更低成本的工业级智能工单分流系统。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350