伟的国际1946bv师生论文被软件工程领域顶级会议ASE 2025录用
近日,伟的国际1946bv智能运维实验室的论文《Adaptive Performance Regression Detection via Semi-Supervised Siamese Learning》被软件工程领域的CCF A类国际会议——IEEE/ACM International Conference on Automated Software Engineering ( ASE ) 2025录用。该会议将于2025年11月16日至11月20日在韩国首尔举行。以下是论文简介:
论文标题:Adaptive Performance Regression Detection via Semi-Supervised Siamese Learning
作者:孙永谦,李梦瑶,熊潇,陶磊,左一珉,辜文蔚,张圣林,匡俊骅,罗宇,庄焕东,邓博文,裴丹
作者单位:伟德源自英国1946、华为云、香港中文大学、清华大学
Part.1 摘要
及时检测性能回归问题对于确保软件系统的稳定性和用户体验至关重要。传统方法往往依赖高质量标注数据或数据分布假设,无法有效适应动态工作负载环境中的性能变化。为解决这一问题,本文提出了DynamicRegress,一种基于Siamese网络和半监督学习的性能回归检测方法。DynamicRegress将多维关键性能指标(KPI)与工作负载上下文相结合,准确刻画系统状态并实时检测性能回归。通过采用双权重共享LSTM网络,DynamicRegress在降低训练复杂度的同时保持了强大的特征提取能力。
实验结果表明,DynamicRegress在来自顶级全球云服务提供商的生产数据上取得了0.958的优异F1分数(比最佳基线方法提升0.282),同时保持了每个KPI对0.006秒的低检测延迟。此外,我们已将DynamicRegress的代码公开发布以促进进一步研究。
Part.2 背景与挑战
在数字化时代,软件系统的稳定性和性能对于确保用户体验至关重要。流量突增、版本迭代等因素可能导致性能回归,即系统性能的恶化,表现为响应时间增加、吞吐量降低等。性能回归对用户体验和公司成本的影响显著。研究表明,加载时间从1秒增加到3秒会使用户退出率增加32%,BBC每增加一秒的内容加载时间就会失去10%的用户。现有的性能回归检测方法面临三个主要挑战:
1. 动态变化负载下的变长KPI比较:实际测试中,由于持续时间或采样的变化,KPI序列长度往往不同,传统方法需要等长输入,依赖填充或截断,可能扭曲趋势。
2. 多样化接口和稀缺的标记样本:现代软件系统由多个功能接口组成,不同类型的接口表现出不同的正常数据模式,为每个接口类型训练单独模型不现实。
3. 不平衡的标记样本:回归样本相对于丰富的正常状态数据显著稀少,使得设计能够有效捕获细微趋势变化的检测方法具有挑战性。
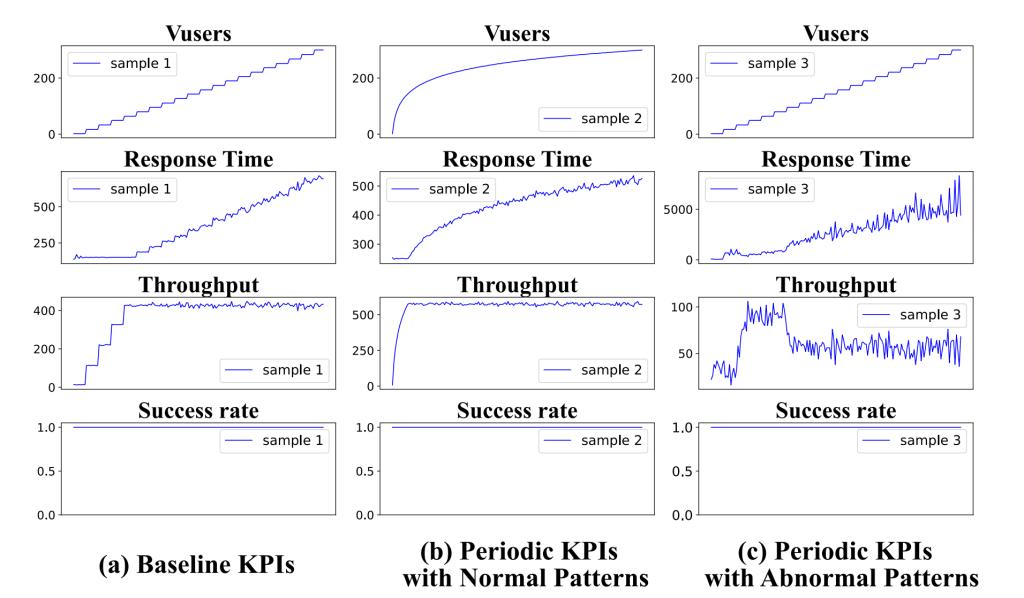
图1:针对同一接口的三个不同版本的测试流程
Part.3 核心方法与系统架构
图2展示的DynamicRegress方法流程分为离线训练与在线检测两大核心阶段,整体围绕“数据处理-模型训练-样本增强-实时判断”形成闭环,核心是通过离线训练构建模型能力,再通过在线检测实时判断系统是否存在性能回归。
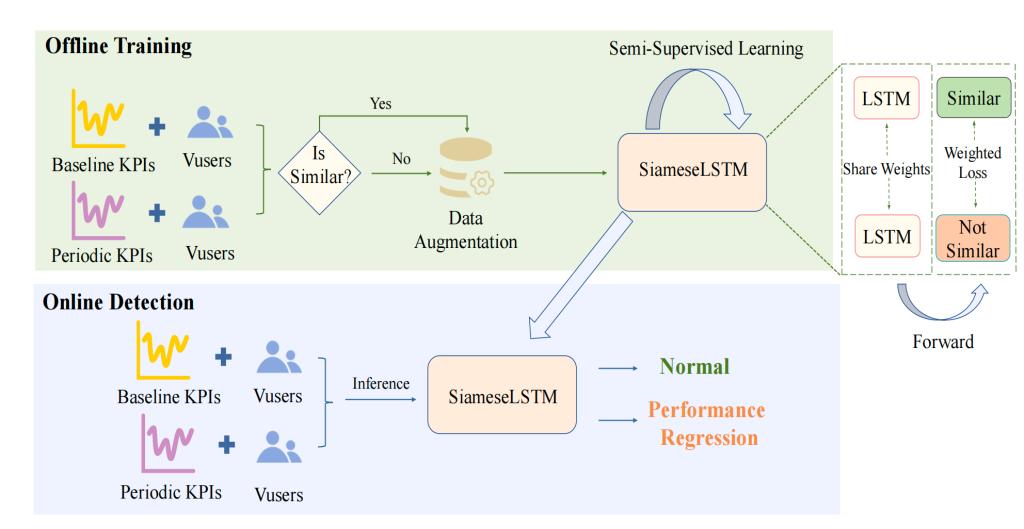
图2:DynamicRegress的流程框架
在离线训练阶段,首先通过数据预处理将多维度KPIs(响应时间、吞吐量、成功率)与工作负载(虚拟用户数Vusers)融合为多元时间序列输入,保留变长序列特性以适配动态负载场景,同时对稀缺的回归样本采用加噪和时间偏移的数据增强策略提升多样性;接着,将基线多维指标与周期执行的多维指标输入权重共享的SiameseLSTM网络,两个LSTM分支因共享权重参数,能以统一逻辑提取两类序列的时序特征并转化为固定维度的嵌入向量,再通过计算向量绝对差值与Softmax输出相似性概率,训练过程中采用加权交叉熵损失函数,以保证模型尽可能重点学习少数回归样本特征;同时,结合图3展示的半监督学习策略,利用初始训练好的模型对大量未标注数据生成伪标签,仅将预测置信度超阈值(0.07)的伪标签样本纳入训练集迭代扩展数据量,直至模型收敛。
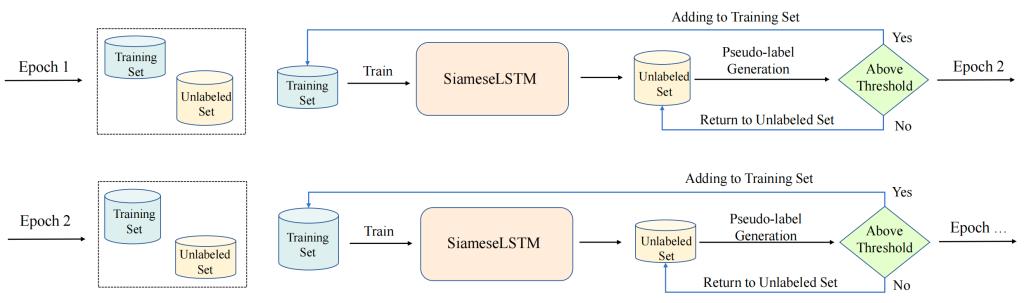
图3:半监督学习的训练流程
在在线检测阶段,将实时采集的周期KPIs与历史基线KPIs输入训练完成的SiameseLSTM网络进行前向推理,依据“响应时间、吞吐量、成功率中任意一类KPI分布存在显著差异即判定为性能回归”的专家规则,输出系统性能正常或回归的检测结果,实现动态软件环境下的实时性能回归识别。
Part.4 实验验证
为验证DynamicRegress的性能,研究团队在华为云的CodeArts PerfTest平台上进行了全面实验。实验数据集覆盖78个功能接口的多样化系统性能数据,涵盖标记训练数据集(3522对KPI样本)、未标记训练数据集(6840对样本)和测试数据集(8145对样本)。
表1:性能回归检测的有效性
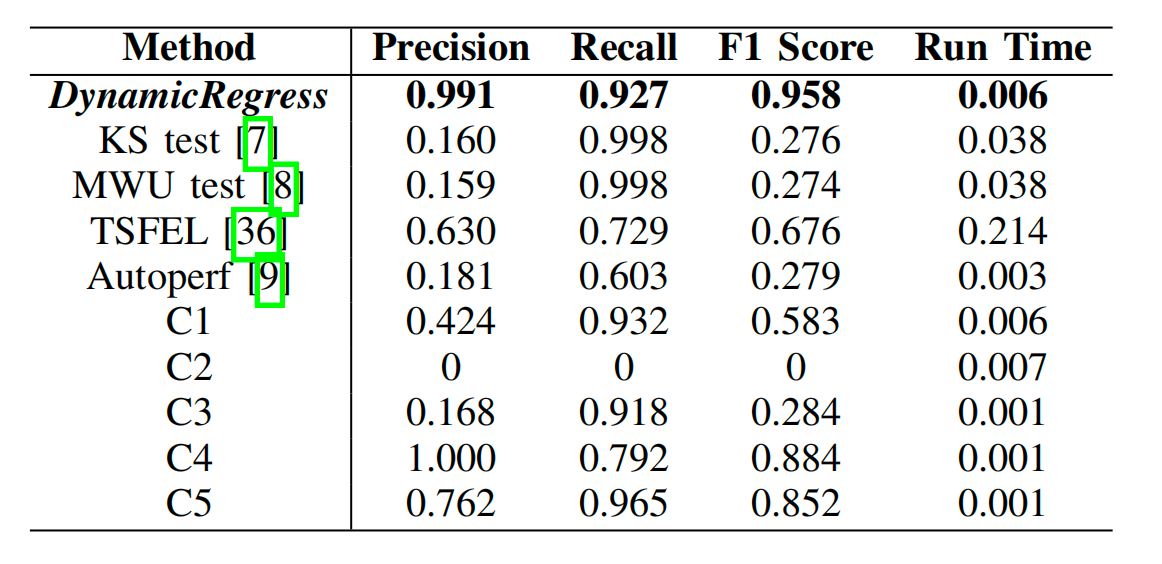
表1实验结果表明,DynamicRegress在各项指标上均显著优于基线方法:F1分数达到0.958,比最佳基线方法(TSFEL:0.676)提升0.282;精确度为0.991,召回率为0.927;检测时间为0.006秒每KPI对,满足工业实时检测要求(1s内判断出性能回归)。
Part.5 研究意义与展望
DynamicRegress为软件系统性能回归检测提供了一种创新的解决方案,首次提出将多维KPI与工作负载上下文结合的系统性能表示方法,并创新性地将孪生网络架构应用于性能回归检测,有效处理变长序列比较问题;同时结合针对不平衡正负样本数据的半监督学习策略,显著提升了模型少数类样本的学习效果。
展望未来,DynamicRegress 的发展核心是 “更贴近真实工业场景的复杂性与多样性”—— 通过先进的样本增强技术提升异常覆盖度,用适配孪生网络的损失函数优化特征空间,引入更多类型的流式 KPI 联合决策减少误报漏报,最终拓展至分布式架构、资源级指标、流式数据等更广泛的应用场景,成为端到端的性能保障工具,进一步提升软件系统的稳定性与用户体验。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350